심심할 때 딥러닝 공부를 하고자 Deep Learning from Scratch 책을 보며 틈틈이 공부하고 있다.
이번에 multi-layer로 이루어진 신경망을 구현하여 학습을 시키고 overfitting을 관측하고자 했는데, 책에 있는 결과를 재현하지 못해 엄청 애먹었다.
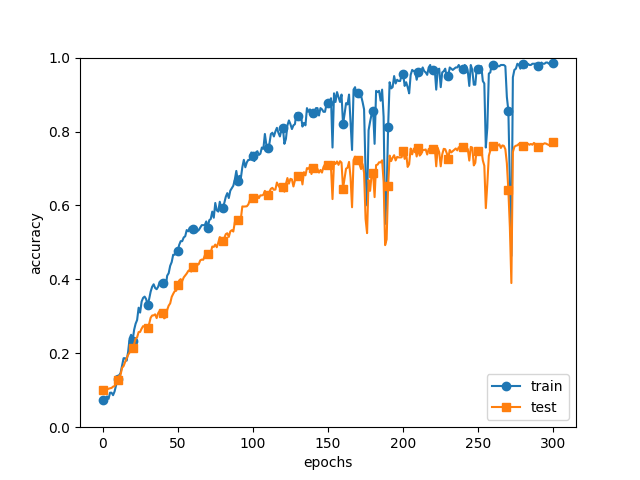
Overfitting을 일부러 일으키고자, 데이터의 개수를 300개로 줄이고 훈련을 시켰다. 그에 비해 신경망의 층수는 6층이니, overfitting이 일어나고, 그래프의 마지막 부분에서도 알 수 있듯이 실제로 overfitting이 일어났다.
그런데 이제 문제가 되는 부분은, 150~200 epoch 사이, 그리고 250~275 epoch 부근에서 정확도가 요동치는 부분이었다. 이게 왜 그런 걸까 싶어서 한참을 고민하다가, 일단 내 수준에서는 여러 번 반복 실험을 해서 결과를 뽑아보는 방법밖에 없겠다 싶었다. 그래서 1년 전 삼성에서 BERT 모델을 다루며 hyperparameter tuning을 했던 기억을 떠올리며 실험을 여러 번 해보기로 했다.
단순히 overfitting을 관측하려고 작성했던 코드이기에, 특별히 상황이 복잡하지는 않았다. Dropout, regularization 등을 적용하지 않아 batch size, epoch 수, learning rate 정도를 조절하면 되는 아주 간단한 상황이었다.

Learning rate를 0.05로 올려서 실행한 결과이다. 학습을 빨리 했는지, 정확도가 1에 도달하는 것처럼 보인다. 하지만 learning rate가 커져서 그런지, 이전에 비해 fluctuation이 훨씬 심해진 것 같은 느낌이 든다.
따라서, 어딘가에서 코딩 실수를 했을 것이라 생각하고 틀린 부분을 찾기 위해 작성해 둔 소스 코드를 엄청나게 뒤져보았다. Network를 구현한 부분, optimizer를 구현한 부분, 각 layer를 종류별로 구현한 부분 등을 다시 차근차근 읽어보며, 틀린 부분을 찾기 위해 이것저것 고쳐보고, 책의 소스코드를 담고 있는 repository에서 코드를 참고하기도 했으나, 이상한 부분을 찾지 못했다.
스스로는 찾지 못해, 책의 소스코드를 담고 있는 repository의 코드를 복사해와 내 코드를 일부분만 교체하여 코딩 실수가 어디에서 발생했을지 찾기로 했고, network를 구현한 부분에서 문제가 생겼다는 사실을 깨달았다.
그렇게 한참을 들여다본 결과, 전혀 예상하지 못했던 부분에서 실수를 했다는 사실을 깨달았다.
# Create layers
activation_layer = {"sigmoid": Sigmoid(), "relu": Relu()}
self.layers = OrderedDict()
for idx in range(1, self.hidden_layer_num + 1):
self.layers["Affine" + str(idx)] = Affine(
self.params["W" + str(idx)], self.params["b" + str(idx)]
)
self.layers["Activation_function" + str(idx)] = activation_layer[activation]코드의 detail은 무시하더라도 혹시 틀린 부분이 보이는가? ㅎㅎ. 눈치가 빠른 분들은 제목을 떠올려 dictionary의 사용법에 뭔가 문제가 있었음을 깨달았을 것이다.
# Create layers
activation_layer = {"sigmoid": Sigmoid, "relu": Relu}
self.layers = OrderedDict()
for idx in range(1, self.hidden_layer_num + 1):
self.layers["Affine" + str(idx)] = Affine(
self.params["W" + str(idx)], self.params["b" + str(idx)]
)
self.layers["Activation_function" + str(idx)] = activation_layer[activation]()이 코드가 올바른 코드이다. 상황을 조금 분석하기 위해 설명을 하자면 Sigmoid, Relu는 둘 다 python class이다.
잘못 구현했던 상황을 좀 단순화시켜보자. 클래스가 하나 필요하고 dictionary가 필요할 것이다. 그리고 그 클래스의 instance를 3개 정도 가진 (python) list를 만들어 보고자 한다. 이 정도 상황이면 충분하다.
class Foo:
def __init__(self):
self.value = 1
dic = {"Foo": Foo()}
l = []
for i in range(3):
l.append(dic["Foo"])분명 의도는 list에 Foo 클래스의 instance를 3개 저장하는 것이다. 그런데 정말 instance가 3개일까? 답은 '아니다'이다.
print(l[0] is l[1])
print(l[1] is l[2])Python의 is operator를 사용하면 variable이 현재 저장되어있는 (memory) address를 비교할 수 있게 된다. 정말 instance가 3개 생성되었다면, 각각 다른 메모리 공간에 존재해야 할 것이다. 하지만 실행 결과는 True, True이다.
따라서, 실제로 클래스 Foo의 instance는 1개만 존재하며, list에 append 하면서 그 instance에 대한 reference만 저장해준 것이라는 결론을 내릴 수 있다. 그러니, list의 한 element를 변경하면, 나머지도 전부 영향을 받게 된다.
l[1].value = 2
print(l[0].value) # 2다시 원래 신경망 훈련으로 돌아가면, 잘못된 코드에서는 activation layer가 애초에 하나만 생성되어 있었고, 이 하나의 layer를 신경망의 각 층에서 공유하고 있었다는 의미가 된다.
Layer에는 forward, backward method들이 각각 구현되어 있었는데, back propagation을 위해 각 layer들은 계산한 결과를 저장하고 있었다. Sigmoid layer의 경우에는
\[\frac {d\sigma(x)}{dx} = (1-\sigma(x))\sigma(x)\]
라는 유명한 결과가 있다. 그래서 이 layer에서는 forward를 한 번 실행하고 그 output를 저장해 두고 있었는데, 위 코드처럼 하나의(같은) layer가 신경망의 각 층에서 공유되고 있었다면, 마지막 forward의 값을 이용해 모든 layer에 back propagation를 시행하고 있었다는 의미가 된다. 당연히 결과가 정상적으로 나올 리가 없다.
원래 의도했던 방식대로 구현하려면 다음과 같이 수정하면 된다.
class Foo:
def __init__(self):
self.value = 1
dic = {"Foo": Foo}
l = []
for i in range(3):
l.append(dic["Foo"]())이 방식에서는 dictionary가 Foo 클래스를 담고 있고 for문에서 생성자를 한 번씩 호출한다. 이 경우에는 생성자가 3번 호출되었으므로, instance도 3개 생성되며, is operator를 이용해 list의 원소가 모두 다른지 확인해 보면 정말 다르다는 것을 (메모리 상의 다른 위치에 저장되어 있는 것을) 확인할 수 있다.
아무튼, 문제를 발견했으니 신경망을 성공적으로 고칠 수 있었고, 정상적인 실험 결과를 얻을 수 있었다.

대략 111 epoch부터 정확도가 계속 100%였고, 원하던 대로 overfitting을 잘 관찰할 수 있게 되었다.
돌이켜 보니, 그동안 자주 사용해온 Java에서도 class를 parameter로 갖는 method의 경우, instance의 주소를 value로 사용해 method를 호출해 왔다. (call by value) 절대로, 그 instance를 복사하지 않았다. 애초에 그렇게 구현하면 함수 호출의 오버헤드가 너무 커진다.
이러한 기본적인 사실을 망각하고 있었음에 엄청난 자괴감이 들었다. 위 신경망의 경우에서도, for문 안에서 dictionary 내부의 layer를 가져오는데, 매번 가져올 때마다 layer (object)가 통째로 복사될 것이라 대충 생각하고 구현한 것 아닌가. 실제로는 reference만 가져온다는 것을 확인했지만, 설령 통째로 복사가 일어난다고 하더라도 그런 비효율적인 코드를 작성하는 안 되는 것이었다. 차라리 생성자를 호출해서 새로 instantiation을 했어야지.
나는 python을 사용할 줄 모른다는 사실을 다시 한번 깨닫게 되었다.
'Computer Science > Machine Learning' 카테고리의 다른 글
| Autodiff with Julia (0) | 2021.03.22 |
|---|---|
| Autodiff 직접 구현하기 (0) | 2021.03.21 |
| Derivative of log determinant (0) | 2020.08.09 |
| Back-propagation on Affine Layers (8) | 2020.04.20 |



댓글