3장에서는 pod 를 직접 관리하는 방법에 대해 살펴봤다. 하지만 실무에서는 pod 의 관리가 자동으로 되길 원한다. 이를 위해 ReplicationController 나 Deployment 를 사용한다.
4.1 Keeping pods healthy
Pod 내의 컨테이너가 (오류로 인해) 죽으면, Kubelet 이 자동으로 해당 컨테이너를 재시작한다. 하지만 컨테이너의 프로세스가 종료되지 않았는데 어플리케이션이 동작하지 않는 경우가 있고, (JVM OOM 에러) 어플리케이션이 deadlock 이나 무한 루프에 빠져서 동작하지 않는 경우가 생길 수도 있다. 이런 경우에도 컨테이너가 자동으로 재시작되게 해야한다. 물론 앱이 자체적으로 에러를 감지해서 프로세스를 종료할 수도 있겠지만, 내부적으로 에러를 감지하기 보다는 컨테이너 밖에서 컨테이너의 상태를 확인해야 한다.
(앱이 자체적으로 에러를 감지해서 프로세스를 죽인다면, 에러를 감지하는 로직을 추가로 구현해야 하며, 이는 쿠버네티스에 올린 앱 종류 별로 달라진다. 앱 자체에 의존적인 로직을 구현하고 사용하는 것보다 컨테이너의 밖에서 정해진 방식으로 에러를 감지하는 편이 나을 것 같다.)
4.1.1 Liveness probes
쿠버네티스는 liveness probe 를 이용해서 컨테이너가 동작 중인지 확인한다. Pod 설정에서 컨테이너 별로 이를 지정할 수 있으며, 지정하면 쿠버네티스가 주기적으로 컨테이너의 상태를 확인하게 된다.
컨테이너 상태 확인하는 3가지 방법
- HTTP GET probe: 컨테이너 IP 주소에 GET 요청 보내보기
- 응답 코드가 2xx, 3xx 이면 OK
- 이외의 에러 코드나 응답이 없으면 실패로 간주하고 컨테이너 재시작
- TCP socket probe: 컨테이너의 정해진 포트에 TCP 연결을 시도해서 실패하면 컨테이너 재시작
- Exec probe: 컨테이너 안에서 임의의 명령을 실행하고 exit code 가 0 이 아니면 컨테이너 재시작
4.1.2 HTTP-based liveness probe 만들기
spec:
containers:
- image: luksa/kubia-unhealthy
name: sung
livenessProbe:
httpGet:
path: /
port: 8080livenessProbe 에 설정해주면 된다. httpGet, tcpSocket, exec 으로 그 종류를 설정할 수 있다.
4.1.3 Seeing a liveness probe in action
kubectl get pods <POD_NAME> 을 한 뒤 RESTARTS column 을 보면 재시작 된 횟수를 알 수 있다.
재시작 사유는 kubectl describe 를 이용해 확인할 수 있다. Last State 를 보면 된다.
컨테이너가 종료될 때는 완전히 새로운 컨테이너가 생성된다. 같은 컨테이너가 재시작 되는 것이 아니다.
(그러면 사실 restart 라는 단어가 조금 애매해지는데... 사실은 다른 컨테이너지만 겉에서 보기에는 같다 정도로 이해하면 될 것 같다.)
4.1.4 Liveness probe 추가 설정
Liveness probe 추가 옵션
initialDelaySeconds: 컨테이너가 시작된 직후 첫 liveness 를 체크를 얼마나 미룰 것인지- 기본값 0s
timeoutSeconds: liveness probe 가 실행된 후 몇 초만에 응답이 와야 하는지- 기본값 1s
periodSeconds: liveness probe 를 실행할 주기- 기본값 10s
successThreshold: 컨테이너가 정상적으로 동작한다고 판단할 연속된 liveness probe success 개수- 기본값 1
failureThreshold: 컨테이너가 동작하지 않고 있다고 판단할 연속된 liveness probe failure 개수- 기본값 3
앱이 시작되는 시간이 존재하므로 initialDelaySeconds 를 잘 설정해야 한다. 무거운 어플리케이션의 경우 실행되는데 오래 걸릴 수도 있다.
Exit code
보통 128 + x 로 계산된다. 여기서 x 는 프로세스를 죽인 signal 의 번호이다.
- 137: SIGKILL (128 + 9)
- 143: SIGTERM (128 + 15)
4.1.5 효과적인 liveness probe 만들기
배포할 때 필수! 설정하지 않으면 쿠버네티스는 컨테이너의 프로세스가 실행 중인지만 확인하여 컨테이너의 상태를 확인한다.
- 앱에 health check API 를 만들어서 이를 호출하도록 할 수도 있다.
- 이 경우 앱 자신에 대한 health check 만 하도록 한다. 프론트 서버에서 DB 가 접속이 안된다는 이유로 실패했다고 하면 안된다. 이건 프론트 서버가 아닌 DB 의 문제일 수도 있다.
- Liveness probe 는 가벼워야 한다.
- 자원을 너무 많이 소모해서도 안되고, 지나치게 오래 걸려도 안된다.
- Liveness probe 구현 시 재시도 횟수를 포함하여 구현할 필요 없다.
failureThreshold옵션을 이용한다.
4.2 ReplicationControllers
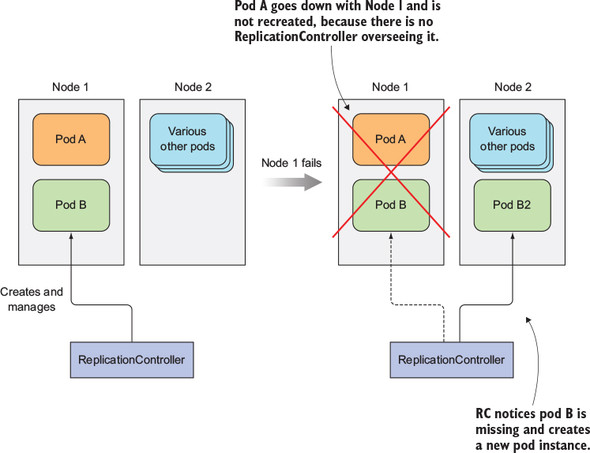
컨테이너가 죽으면 liveness probe 등을 이용하여 다시 재시작하면 된다. 이 작업은 pod 가 존재하고 있는 노드의 Kubelet 이 해준다. 그런데 만약 노드가 죽으면? Control Plane 이 직접 나서서 죽어버린 pod 를 다시 살려야 한다.
다만 직접 만든 pod 에 대해서는 다시 살릴 수 없다. 직접 만든 pod 에는 Control Plane 이 관여하지 않고, 노드에 있는 Kubelet 혼자서 관리하고 있기 때문에, 노드가 죽어서 Kubelet 이 사라지면 되살릴 방법이 없어진다.
노드가 죽은 경우에도 다른 노드에서 pod 가 시작되게 하려면, ReplicationController 와 같은 쿠버네티스 리소스를 사용해야 한다.
근데 docs 보면 다음과 같은 내용이 있다!!!
Note: A Deployment that configures a ReplicaSet is now the recommended way to set up replication.
ReplicationController 는 pod 가 동작하고 있는지 확인하고, pod 의 복제본 개수를 정확하게 관리해준다.
4.2.1 The operation of a ReplicationController
ReplicationController 는 현재 실행 중인 (정상 작동 중인) pod 의 목록을 확인하여 특정 'type' 의 pod 개수가 일정하도록 관리해준다. 만약 pod 개수가 너무 적으면 pod 를 더 띄우고, 너무 많으면 pod 를 삭제한다.
Pod 의 개수가 안 맞는 경우
kubectl등 커맨드로 직접 같은 pod 를 하나 더 생성하는 경우- 존재하는 pod 에서 'type' 을 변경하는 경우
- ReplicationController 에서 필요한 pod 개수를 변경하는 경우
여기서 'type' 이라 함은 pod 들의 부분집합을 말하는데, label selector 를 사용하여 얻은 부분집합이다.
동작 방식은 간단하다. 정해진 label selector 에 맞는 pod 의 개수를 확인하여 정해진 만큼 있으면 아무 것도 하지 않는다. Pod 개수가 적거나 많으면 더 만들거나 삭제한다.
Three parts of a ReplicationController
- label selector: ReplicationController 의 scope (관리할 pod 들) 를 결정할 label
- replica count: 필요한 pod 의 개수를 정함
- pod template: 새로운 pod 를 만들 때 사용할 template
이 세 가지는 ReplicationController 가 실행된 이후에도 수정이 가능하지만, replica count 를 수정하면 현재 실행 중인 pod 에 영향을 미치게 된다.
Label selector 를 고치게 되면 ReplicationController 의 scope 에서 pod 이 빠지게 된다. (근데 그러면 변경된 label selector 에 따라서 새로운 pod 들이 scope 에 들어오게 되면 existing pod 에 영향을 주는 것 아닌가?)
궁금해서 테스트 해봤다.
- 우선
app=kubialabel 이 달린 pod 3개를 생성하고, ReplicationController 를 만들어app=kubia2label 을 가진 pod 를 2개 생성 - ReplicationController 에서
template의label을app=kubia로 변경 kubectl apply -f를 이용해서 존재하는 object 를 수정 (create쓰면 삭제되고 다시 만드니까)- 에러가 뜨며 수정이 불가능
- 한번 ReplicationController 를 생성할 때
selector가 정해졌는데,template의label을 바꾸면selector와 값이 달라지게 되므로 에러 - 그럼 ReplicationController YAML 에서
selector도app=kubia로 명시적으로 적기 (앞에서는 안적었음) - 다시
kubectl apply -f를 하니 적용이 됐고,app=kubia가 달려있던 pod 3개 중 하나가Terminating으로 변경됨 - 그러면 existing pod 에 영향을 주는 것 같으니 책의 의도는 "기존 scope 에 있던 existing pod" 에 영향을 주지 않는 다는 말인 듯 (;;)
그리고 ReplicationController 는 pod 를 생성하고 나면 pod 의 내용 (컨테이너 이미지, 환경 변수 등) 은 신경쓰지 않기 때문에 pod template 을 수정해도 기존 pod 에는 영향을 주지 않는다.
ReplicationController 의 장점
- 실행 중인 pod 의 개수를 일정하게 유지해준다.
- 클러스터 노드가 죽는 경우, 노드 안에 있던 pod 중 ReplicationController 의 scope 안에 있는 pod 를 살려내 준다.
- Scale out 을 쉽게 해준다.
4.2.2 ReplicationController 만들기
apiVersion: v1
kind: ReplicationController
metadata:
name: sung-rc
spec:
replicas: 3 # 복제본 3개
selector: # label selector
app: kubia
template: # pod template
metadata:
labels:
app: kubia
spec:
containers:
- name: sung
image: luksa/kubia
ports:
- containerPort: 8080selector 를 명시할 필요는 없다. template 의 label 을 보고 자동으로 뽑아준다. (selector 의 label 이 spec 의 label 과 달라서 컨테이너가 무한히 생성되는 문제를 막기 위해서 이를 검사한다)
4.2.3 Seeing the ReplicationController in action
컨테이너를 하나 삭제해 보면 즉시 새로운 컨테이너가 하나 생기는 모습을 확인할 수 있다.
동작 방식: ReplicationController 는 scope 내의 pod 가 삭제되면 삭제된 사실을 알게 된다. 그러면 ReplicationController 는 pod 의 개수가 적절한지 확인하게 되고, 만약 적절하지 않으면 적당한 행동을 취해 pod 수를 조정한다.
kubectl get rc 를 하면 ReplicationController 별로 DESIRED, CURRENT, READY 컨테이너 수를 확인할 수 있다.
(노드를 죽이는 실습은 생략)
4.2.4 ReplicationController 의 scope 조절하기
ReplicationController 가 생성한 pod 은 ReplicationController 와 직접 연결되어 있지 않다. 단지 ReplicationController 는 label selector 에 맞는 pod 들을 관리할 뿐이다. 그러므로 pod 의 label 을 변경하게 되면 scope 에 들어가거나 나갈 수 있다.
Label 을 변경해서 scope 에서 나가게 되면 ReplicationController 를 사용하지 않고 만들어진 pod 과 다를 바가 없게 된다. 노드가 죽으면 끝이다. 또한 pod 를 관리하고 있던 ReplicationController 를 삭제하면 scope 를 벗어난 pod 는 제거되지 않는다.
ReplicationController 의 label selector 수정하기
(아 혼자 테스트 해봤는데 내용이 책에 있었네)
ReplicationController 의 label selector 를 수정하게 되면 기존 scope 에 있던 pod 들은 모두 scope 에 포함되지 않게 되며, 새로운 label selector 를 이용해 조회한 pod 목록을 보고 ReplicationController 는 적절한 동작을 취한다.
4.2.5 Pod template 수정하기
Template 이 바뀐다고 해서 기존에 scope 에 있던 pod 들이 갑자기 사라지거나 하지는 않으므로, 기존 pod 를 하나 지우게 되면 ReplicationController 가 새로 pod 생성할 때 변경된 template 으로 생성한다.
4.2.6 Horizontal scaling
$ kubectl scale rc <RC_NAME> --replicas=<REPLICAS>혹은
$ kubectl edit rc <RC_NAME>으로 YAML 파일을 직접 수정하여 scaling 을 할 수 있다. 개수만 바꿔주면 나머지는 ReplicationController 가 알아서 한다.
4.2.7 ReplicationController 삭제하기
kubectl delete 를 사용하면 scope 내의 pod 도 같이 지워진다! 단 --cascade=false 옵션을 주면 ReplicationController 만 지워지고 pod 는 남아있게 된다.
Pod 가 관리되지 않은 채로 남아있다고 하더라도, 다시 ReplicationController 를 생성해서 얼마든지 다시 관리할 수 있다.
4.3 ReplicaSet
ReplicationControllers will eventually be deprecated!
보통 ReplicaSet 은 Deployment 를 생성할 때 자동으로 만들어진다.
4.3.1 ReplicaSet 과 ReplicationController 비교
ReplicaSet 의 pod selector 가 표현력이 훨씬 강하다. ReplicationController 는 특정 label 을 포함하는지만 검사가 가능하지만, ReplicaSet 의 경우 label 이 없는지, 혹은 특정 label key 를 갖는지 검사할 수 있다.
4.3.2 ReplicaSet 정의하기
apiVersion: apps/v1 # apps API group 에 있다
kind: ReplicaSet
metadata:
name: sung
spec:
replicas: 3
selector: # 이 부분만 다르다
matchLabels:
app: sung
template: # ReplicationController 와 동일
metadata:
labels:
app: sung
spec:
containers:
- name: sung
image: luksa/kubia4.3.3 Creating and examining a ReplicaSet
kubectl get rs 로 ReplicaSet 의 목록을 확인할 수 있다.
4.3.4 More expressive label selectors
matchLabels 는 ReplicationController 의 label selector 와 동일하다.
matchExpressions property 를 이용해서 더욱 복잡한 label selector 를 이용할 수 있다.
selector:
matchExpressions:
- key: app
operator: In
values:
- sung각 expression 에는 세 가지 값이 필요하다. key, operator, values (optional).
key: label 의 key 값operator: 네 개가 있다.In: label 의 value 가values안에 있는지 검사NotIn: label 의 value 가values안에 없는지 검사Exists:key를 갖고 있는지 검사 (values옵션 불필요)DoesNotExist:key를 갖고 있지 않은지 검사 (values옵션 불필요)
여러 개의 expression 을 사용하면 모든 expression 을 만족해야 pod 가 선택된다.
4.3.5 ReplicaSet 정리
항상 ReplicationController 대신 ReplicaSet 을 사용해라!
4.4 DaemonSet 을 이용하여 한 노드에 pod 하나씩 실행하기
ReplicationController 나 ReplicaSet 을 사용하면 클러스터 내의 임의의 노드에서 실행하게 되는데, 각 노드마다 하나씩 존재해야 하는 앱이 있을 수도 있다. (한 노드가 여유롭다고 몰리면 안된다) 대표적으로 노드의 리소스를 확인하거나 노드의 로그를 확인하고 싶은 경우가 그렇다.
쿠버네티스를 사용하지 않는다면 system init script 나 systemd 를 사용할 것이고, 노드에서 이것들을 사용할 수 있긴 하지만, 쿠버네티스의 장점은 누릴 수 없게 된다.
4.4.1 DaemonSet 으로 모든 노드에 pod 띄우기
ReplicaSet 과 거의 비슷하지만 DaemonSet 을 사용하면 Kubernetes Scheduler 의 통제를 받지 않게된다. DaemonSet 은 노드 개수 만큼 pod 을 만들며, 각 노드마다 pod 를 하나씩 올린다.
DaemonSet 은 replica count 의 개념이 없으며, 단지 모든 노드에 pod 가 하나씩 동작하고 있는지만 관리한다. 그러므로 노드가 죽으면 아무 일도 하지 않고, 노드가 새로 생길 때는 바로 pod 를 하나 더 띄워준다.
4.4.2 DaemonSet 으로 특정 노드에 pod 띄우기
Node selector property 를 이용하면 모든 노드가 아니라 특정 노드에만 pod 를 띄울 수 있게 된다.
주의사항: 노드는 unschedulable 상태로 만들 수 있는데, DaemonSet 은 이런 상태를 무시하고 pod 를 띄운다. 이 unschedulable property 는 scheduler 가 이용하는데, DaemonSet 은 scheduler 의 영향을 받지 않기 때문이다. 더불어 이 동작은 의도된 것이다. DaemonSet 은 시스템과 관련된 서비스를 운영할 때 사용하므로 unschedulable node 에도 pod 를 띄워야 한다.
YAML 파일은 ReplicaSet 과 거의 동일한데, node selector 를 사용한다는 차이점이 있다.
template:
...
spec:
nodeSelctor: # node selector 를 사용한다.
disk: ssd4.5 Running pods that perform a single completable task
여기서 single completable task 란, 동작을 모두 마치면 종료하는 작업을 말하는 것이다. (기존에는 서버와 같이 계속 실행 중이어야 하는 프로세스를 다뤄왔다. 이 프로세스들은 완료 - 'completed' 의 개념이 없다)
4.5.1 Job 리소스
Job 리소스를 사용하면 작업이 완료된 뒤에 재시작 되지 않는 pod 를 만들 수 있게 된다.
만약 노드가 죽는 경우에는 다른 노드로 다시 스케줄링 되며, 만약 컨테이너의 프로세스가 문제가 생긴 경우 컨테이너를 재시작할지 그냥 종료할지 선택할 수 있다.
Job 은 정상적으로 종료되어야 하는 task 에 사용하는 것이 좋다. 쿠버네티스나 Job 을 사용하지 않고도 작업을 할 수 있겠지만, 쿠버네티스를 사용하면 노드가 죽거나 에러가 생기는 경우에 쿠버네티스의 기능을 활용하여 작업이 정상적으로 완료될 때까지 다시 실행할 수 있게 된다.
4.5.2 Job 리소스 정의하기
apiVersion: batch/v1
kind: Job
metadata:
name: batch-job
spec:
template:
metadata:
labels:
app: batch-job
spec:
restartPolicy: OnFailure # 문제가 생겼을 때 어떻게 할지
containers:
- name: main
image: luksa/batch-job restartPolicy 는 일반적으로 Always 이다. 하지만 Job 리소스를 만들 때 이 값을 사용할 수는 없고, OnFailure 혹은 Never 를 사용하게 된다. (계속 실행할 거면 Job 을 쓰지 말자) 이 옵션 값을 사용하므로 작업이 완료된 뒤 컨테이너가 재시작되지 않는다.
4.5.3 Seeing a Job run a pod
Job 을 생성한 뒤 완료되면 pod 의 상태가 Completed 로 변경되고, 삭제되지 않은 채로 남아있다. 실행 결과 로그를 확인할 수 있게 하기 위해서이다. 단, Job 을 삭제하면 pod 도 같이 삭제된다.
4.5.4 Running multiple pod instances in a job
Job 은 꼭 하나의 pod 만 생성해야 하는 것은 아니다. 순차적 실행, 병렬 실행도 가능하다.
순차적 실행
...
spec:
completions: 5 # 5번 완료되어야 Job 이 완전히 끝난다completions 옵션을 사용하면 지정된 횟수만큼 pod 을 만들어서 작업을 수행한다. 한 번에 pod 하나씩 만들어서 작업을 수행하지만 중간에 작업이 실패하는 경우가 있을 수도 있으므로 총 생성하는 pod 개수는 지정된 값보다 많을 수 있다.
(연속으로 성공해야 하는지? 2개 완료하고 죽으면 처음부터 다시하나? 맥락 상 처음부터 다시 하지는 않을 것 같은데 - 찾아보기)
병렬 실행
...
spec:
completions: 5
parallelism: 2 # 한 번에 만들 pod 개수parallelism 옵션을 사용하면 작업을 동시에 실행할 pod 개수를 설정할 수 있다. 여러 개 중 어느 하나라도 완료되면 바로 다음 pod 를 생성하여 completions 횟수만큼 작업을 완료한다. 이 값은 Job 이 실행 중일 때도 변경 가능하다.
$ kubectl scale job <JOB_NAME> --replicas <NUM_REPLICAS>4.5.5 Job pod 에 제한 시간 걸기
작업이 끝날 때까지 얼마나 기다려야 할지 정할 수 있다. 중간에 무한 루프에 빠지는 등 멈출 수도 있다.
.spec.activeDeadlineSeconds 옵션을 이용하면 지정된 시간 만큼 작업을 실행해보고, 시간이 지나도 완료되지 않으면 실패 처리한다.
더불어 .spec.backoffLimit 옵션을 사용하면 최대 몇 번까지 작업을 재시도할지 설정할 수 있다. 다만 activeDeadlineSeconds 가 더 우선 순위가 높아 시간이 초과되면 재시도 횟수가 남아도 그냥 실패 처리한다.
4.6 Scheduling Jobs to run periodically or once in the future
(당연히 CronJob 같은게 나올 것 같았다)
4.6.1 CronJob 만들기
(얘는 아직 API가 beta 네...)
apiVersion: batch/v1beta1
kind: CronJob
metadata:
name: batch-job-15m
spec:
schedule: "0,15,30,45 * * * *" # 15분마다 실행하기
jobTemplate:
spec:
template:
metadata:
labels:
app: periodic-batch-job
spec:
restartPolicy: OnFailure
containers:
- name: main
image: luksa/batch-job4.6.2 Understanding how scheduled jobs are run
대략 Job 을 실행할 시간대가 되면 CronJob 이 Job 리소스를 생성하고, Job 이 pod 를 만들어서 작업을 실행한다.
이 생성 작업이 조금 걸릴 수도 있으므로, .spec.startingDeadlineSeconds 옵션을 설정하여 정해진 시간으로부터 늦어도 몇 초 이내에 작업이 실행되어야 하는지 설정할 수 있다.
만약에 정해진 시간이 지나도 실행하지 못했다면 자동으로 실패처리 된다.
CronJob 은 보통 1회 실행 시 Job 를 하나 만들지만, 2개 이상이 생성될 수도 있으므로, idempotency 를 가지고 있어야 한다. 여러 번 실행해도 같은 결과를 보장해야 한다. 또한 직전에 실패한 경우가 있다면 다음 Job 은 직전에 실패한 것까지 고려해야할 수도 있다.
'Computer Science > Kubernetes' 카테고리의 다른 글
| Chapter 7. ConfigMaps and Secrets: configuring applications (0) | 2021.04.18 |
|---|---|
| Chapter 6. Volumes: attaching disk storage to containers (0) | 2021.04.07 |
| Chapter 5. Services: enabling clients to discover and talk to pods (0) | 2021.04.07 |
| Chapter 3. Pods: running containers in Kubernetes (0) | 2021.03.17 |
| Chapter 2. First steps with Docker and Kubernetes (0) | 2021.03.08 |
| Chapter 1. Introduction to Kubernetes (2) | 2021.02.28 |




댓글