주요 내용
- HPA 리소스 이해하고 사용하기
- 클러스터 노드의 automatic scaling
수동으로 scaling (수평) 을 하는 경우 ReplicationController, ReplicaSet, Deployment 등에서 replicas field 를 고쳐줘야 했다.
이번 장에서는 pod 나 노드의 상태에 따라 자동으로 scaling 하는 방법을 알아본다.
15.1 Horizontal pod autoscaling
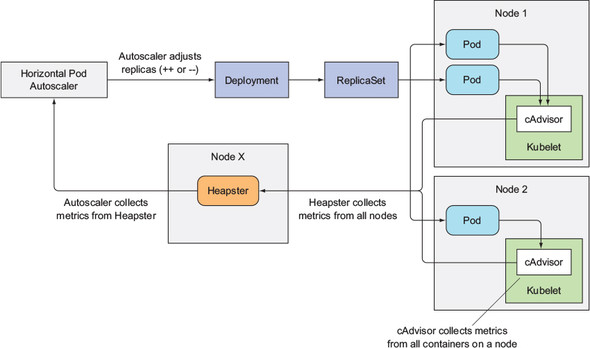
Horizontal pod autoscaling 은 Horizontal controller 가 pod 의 replica 수를 알아서 조절하는 것이다.
이 controller 는 HorizontalPodAutoscaler(HPA) 리소스를 생성하면 활성화 되며, 주기적으로 pod 의 metric 을 확인하고, metric 이 원하는 값에 도달할 수 있도록 replica 수를 조절한다.
15.1.1 Understanding the autoscaling process
Autoscaling 은 3단계로 일어난다.
- Scaled resource object 가 관리하는 모든 pod 의 metric 수집
- Scaled resource object 라 함은 ReplicationController, ReplicaSet, Deployment 등 scaling 을 관리하는 오브젝트
- Metric 값이 원하는 값(target value)에 최대한 가깝게 하기 위해 필요한 pod replica 수 계산
- HPA 에 어떤 metric 값이 얼마에 도달하기를 원하는지 정의할 수 있다
- Scaled resource 의
replicasfield 를 업데이트
Pod metric 수집
14장에서 살펴본 것처럼 cAdvisor 에서 metric 을 수집하고 이를 Heapster 로 보낸다. 그리고 HPA 는 Heapster 를 REST API 로 호출하여 정보를 얻어온다.
Heapster 는 deprecated 되었으므로, 아마 metrics-server 에서 가져오지 않을까?
한 가지 유의할 점은 여러 단계를 거쳐 정보를 받아오므로, 정보가 전파되는데 시간이 조금 걸리기 때문에 scaling 이 실제로 시작되기까지는 delay 가 있을 수 있다.
필요한 pod 개수 계산
Metric 을 하나만 사용하는 경우에는 모든 pod 의 metric 값을 합해서 이를 target value (HPA 에 지정한 원하는 값) 로 나누고 정수로 올림한다.
예를 들어 CPU의 target value 가 50% 인데, 3개의 pod 의 CPU metric 합이 270% 라면, 270 / 50 = 5.4 이고 정수로 올려서 6개의 pod 가 필요하게 된다.
물론 실제 계산은 이보다 복잡하다. 순간적으로 CPU 사용률이 요동을 치는 경우 HPA 가 이에 민감하게 반응하지 않도록 처리한다.
만약 metric 을 여러 개 사용하는 경우에는 각 metric 별로 요구하는 pod 개수 중 최댓값을 택한다.
replicas field 업데이트
HPA 와 scaled resource object 사이에 한 단계의 추상화 interface layer 를 두어 HPA 는 scaled resource object 의 세부 스펙을 몰라도 되게 해두었다.
Scale sub-resource 가 해당 layer 역할을 하고, HPA 는 Scale 의 replica count 만 조작하고, 실제고 scaled resource object 의 replicas field 를 업데이트 하는 것은 Scale 이다.
Scale 가 지원하는 scaled resource object 에는 Deployments, ReplicaSets, ReplicationControllers, StatefulSets 등이 있다.
15.1.2 Scaling based on CPU utilization
Autoscaler 는 pod CPU requests 에 설정한 값에 비해 실제로 얼마나 쓰고있는지를 계산하여 pod CPU utilization 을 계산한다.
따라서 autoscaling 을 위해서는 CPU requests 값을 설정해둬야 한다.
HPA 를 실제로 생성하기 위해서는 다음 명령어를 입력하면 된다.
$ kubectl autoscale deployment <DEPLOYMENT_NAME> --cpu-percent=<PERCENT> --min=<MIN> --max=<MAX>PERCENT는 target value 로 지정할 CPU utilization 이다.MIN,MAX는 scaling 으로 조절할 수 있는 pod 개수의 최솟값/최댓값이다.
Deployment 를 autoscale 하는 것이 권장된다. ReplicaSet 을 직접 autoscale 하는 경우 프로덕션 환경에서 pod 이 업데이트 할 때 Deployment 가 새로운 ReplicaSet 을 생성하면 HPA 를 다시 붙여야 한다.
YAML manifest 는 이렇게 생겼다.
apiVersion: autoscaling/v1
kind: HorizontalPodAutoscaler
metadata:
...
name: kubia
spec:
maxReplicas: 5
minReplicas: 1
scaleTargetRef:
apiVersion: apps/v1
kind: Deployment
name: kubia
targetCPUUtilizationPercentage: 30
status:
currentReplicas: 3
desiredReplicas: 0HPA 를 생성한 뒤 kubectl get hpa 를 해보면 아직 CPU 정보가 없어 <unknown> 이라고 나오는 것을 볼 수 있다.
$ kubectl get hpa
NAME REFERENCE TARGETS MINPODS MAXPODS REPLICAS AGE
kubia Deployment/kubia <unknown>/30% 1 5 3 47sMaximum scaling rate
Autoscaler 가 scaling 을 할 때 한 번에 생성할 수 있는 pod 개수에 제한이 있다.
만약 현재 replica 수가 1~2 이면 최대 replica count 는 4로 제한된다. 만약 3 이상인 경우에는 replica count 는 최대 현재의 2배로 제한된다.
추가로 autoscale event 를 시도할 수 있는 시간에 대한 제약도 있다. Scale-up 의 경우 지난 3분간 rescaling 이 없었어야 하고, scale-down 은 5분마다 시도한다. Metric 값이 갑작스럽게 변경되었지만 최근에 scaling 이 일어났다면 HPA 가 바로 반응하지 않을 수도 있다.
15.1.3 Scaling based on memory consumption
메모리의 경우는 CPU와 달리 scaling 하기가 어렵다. Pod 를 더 띄웠다고 해서 기존 pod 가 물고 있던 메모리를 놓지 않을 수도 있기 때문이다.
시스템 측에서 할 수 있는 것이라고는 그저 컨테이너를 죽이고 재시작 한 다음, 메모리를 예전보다 적게 쓰길 바라는 수밖에 없다. 그래서 메모리 해제는 pod 내부의 어플리케이션이 처리해야 하는 부분이다.
Kubernetes 1.8 에서 memory-based scaling 이 나왔다고 한다!
15.1.4 Scaling based on other and custom metrics
HPA 의 .spec.metrics field 는 list 이기 때문에 여러 metric 을 한꺼번에 사용할 수 있다. 각 entry 는 metric type 를 정의한다. HPA 에는 3가지 종류의 metric type 이 있는데, Resource, Pods, Object 가 있다.
Resource metric type
CPU utilization 과 같이 컨테이너의 resource requests 와 관련된 값들이다.
Pods metric type
Pod 와 관련된 metric 들이 여기에 속한다. 예를 들어 queries per second (QPS) 등이 있다.
Object metric type
Scaling 을 결정하는 metric 이 pod 과 직접적인 연관이 없을 때 사용한다. 예를 들면 Ingress object 의 QPS 나 request latency 등을 기반으로 scaling 을 할 수 있다.
Object type 을 쓰게 되면 하나의 object 에서 하나의 metric 을 가져오기 때문에 target object (이름으로) 정해줘야 한다.
15.1.5 Determining which metrics are appropriate for autoscaling
모든 metric 이 autoscaling 에 적합한 것은 아니다. Replica 수를 늘렸을 때 metric 이 감소해야 한다. 그러므로 pod 개수가 증가/감소할 때 metric 이 어떻게 변할지 예측해보고 사용해야 한다.
15.1.6 Scaling down to zero replicas
책이 쓰였을 당시 HPA 에서는 minReplicas 값을 0 으로 설정하는 것을 허용하지 않았다고 한다.
Documentation 에서는 특별한 언급을 찾지는 못했다. 일단
autoscale명령어로--min=0을 주고 생성해도 1 로 설정하는 것이 확인되었다.
15.2 Vertical pod autoscaling
만약 vertical scaling 이 지원됐다면, pod manifest 에서 resource requests 를 수정하는 방식으로 지원했을 것이라고 한다. 하지만 이미 생성된 pod 의 resource requests 는 수정이 불가능하다.
책이 쓰였을 당시에는 vertical pod autoscaling 은 지원이 되지 않았다고 한다.
검색해보니 AWS, GCP 등 클라우드에서 vertical scaling 이야기는 나오는데, 어째서인지 검색 결과 중에 공식 문서는 없다...?
15.2.1 Automatically configuring resource requests
Experimental feature 중에, 새로 생성된 pod 의 CPU/메모리 requests 를 자동으로 설정해주는 기능이 있다. InitialResources 라는 Admission Control plugin 에 의해 동작한다.
자동으로 설정할 때는 과거 같은 컨테이너를 실행한 기록을 참고하여 CPU/메모리 requests 를 설정한다. 어떻게 보면 vertical scaling 을 하고 있는 것인데, 컨테이너가 OOM이 자주 발생했다면, InitialResources 는 그 컨테이너를 실행할 때 메모리를 더 요청한다.
15.2.2 Modifying resource requests while a pod is running
책이 쓰여질 당시 vertical pod autoscaling proposal 이 finalize 되고 있었다고 한다. 공식 문서를 참고해 달라고 한다.
15.3 Horizontal scaling of cluster nodes
Scaling 을 하다 보면 존재하는 노드의 자원을 다 쓰거나 기타 이유로 scheduling 이 불가능해지는 상황이 올 수도 있다.
On-premise 환경이라면 어렵겠지만, 클라우드의 경우 자동으로 노드를 생성해주는데 이를 Cluster Autoscaler 라고 부른다.
15.3.1 Introducing the Cluster Autoscaler
Cluster Autoscaler 는 pod 가 생성되었지만 scheduling 에 실패한 경우 새로운 노드를 생성해주며, 만약 노드의 사용률이 낮으면 (under-utilized) 노드를 알아서 처분해주기도 한다.
클라우드에 새로운 노드 요청
Scheduler 가 scheduling 에 실패했을 때, Cluster Autoscaler 가 동작하며 새로운 노드를 클라우드에 요청한다. 우선 새로운 pod 가 새로운 노드에 띄워질 수 있는지 검사하고, 내부의 알고리즘에 따라 노드 타입을 선택하여 요청을 보낸다.
새로운 노드가 띄워지면 새 노드의 Kubelet 이 API server 에 Node 리소스 생성을 요청하며, 해당 노드는 클러스터의 일부가 되어 동작하게 된다.
책에 내부 알고리즘이 정확하게 나와있지는 않다. 클라우드가 제공하는 노드 종류가 여러 개 있는데, 이 중 어떤 노드가 'best' 인지는 configurable 하다고 적혀있다. 최악의 경우 랜덤으로 고른다고 한다. 근데 비용이 많이 나갈 수도 있는데 설마 이럴 것 같지는 않다.
노드 삭제
만약 한 노드에 존재하는 모든 pod 의 CPU/메모리 requests 가 50% 이하이고, 해당 노드에서만 돌아가는 system pod 가 없으며, (DaemonSet 의 경우 모든 노드에서 돌아가므로 제외) unmanaged pod (Replication 에 의해 관리되지 않음) 나 pod with local storage 가 존재하지 않으면 불필요하다고 판단한다.
조건이 복잡하지만 결국 노드에서 실행 중인 pod 들이 다른 노드로 scheduling 될 수 있고, requests 가 적으면 불필요하다고 판단한다.
노드가 삭제될 것이라고 마킹되면, unschedulable 이라고 마킹되며, pod 들은 전부 삭제된다. 삭제되기 위해서는 애초에 모든 pod 들이 Replication 에 의해 관리되고 있었을 것이므로, 삭제된 pod 대신 다른 노드에 pod 가 자동으로 띄워진다.
kubectl cordon <node>를 하면 노드가 unschedulable 상태가 된다. 하지만 pod 들은 남아있는다.kubectl drain <node>를 하면 unschedulable 상태가 되고 pod 가 전부 삭제된다.
15.3.2 Enabling the Cluster Autoscaler
각 클라우드 공식 문서를 참고하면 된다.
15.3.3 Limiting service disruption during cluster scale-down
몇몇 서비스는 항상 실행되고 있어야 하는 최소 pod 개수가 존재한다. Kubernetes 에서는 PodDisruptionBudget 리소스를 사용하여 최솟값을 설정할 수 있다.
Pod label selector 와 최솟값을 설정해서 생성하면 selector 에 매칭된 pod 의 개수가 최솟값 이상이 되도록 해준다.
$ kubectl create pdb <NAME> --selector=<SELECTOR> --min-available=<MIN>SELECTOR는 pod label selector (key=value)MIN은 사용 가능한 pod 개수의 최솟값
Kubernetes 1.7 부터는 사용 가능한 pod 의 최솟값 대신 사용 불가능한 pod 의 최댓값을
maxUnavailable으로 설정할 수도 있다.
Discussion & Additional Topics
'Computer Science > Kubernetes' 카테고리의 다른 글
| Chapter 18. Extending Kubernetes (0) | 2021.09.04 |
|---|---|
| Chapter 17. Best practices for developing apps (0) | 2021.08.15 |
| Chapter 16. Advanced scheduling (0) | 2021.08.15 |
| Chapter 14. Managing pods' computational resources (0) | 2021.07.11 |
| Chapter 13. Securing cluster nodes and the network (0) | 2021.06.29 |
| Chapter 12. Securing the Kubernetes API server (0) | 2021.06.06 |




댓글