주요 내용
- Kubernetes 리소스에 대한 전반적인 이해
- Pod lifecycle hooks and init containers
17.1 Bringing everything together
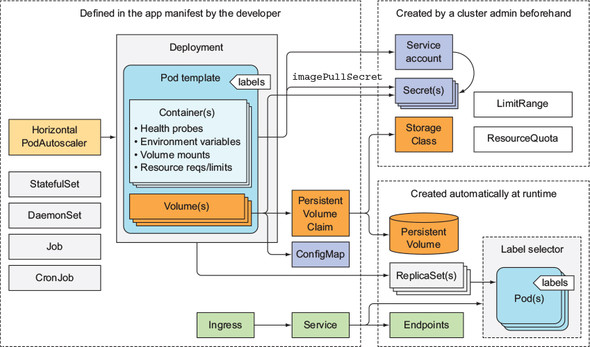
일반적인 어플리케이션이 Kubernetes 위에서 배포될 때 어떤 형태로 하는지, 지금까지 살펴본 것들을 종합하여 알아본다.
일반적으로 어플리케이션을 배포할 때는 Deployment 또는 StatefulSet 을 반드시 사용하게 된다. 이들은 pod template 를 들고 있으며, 거기에는 liveness/readiness probe 가 모두 정의되어 있다.
Service 를 이용해서 외부에서 pod 로 요청을 보낼 수 있도록 하고, 이 Service 는 LoadBalancer 또는 NodePort 타입이나 Ingress 를 이용해 외부로 노출된다.
그리고 pod template 들은 주로 두 종류의 secret 을 '참조'하는데, 첫째는 private image registry 에서 image 를 pull 받기 위해 사용하는 secret 이고, 둘째는 컨테이너 내부에서 사용하는 secret 이다. '참조'만 하는 이유는 secret 의 경우 manifest 에 포함되지 않기 때문에 개발자 생성하는 것이 아니기 때문이다. 주로 클러스터 관리자/Operation team 에서 secret 을 생성하며 ServiceAccount 에 할당되고 pod 가 ServiceAccount 를 이용하는 형태이다.
그 밖에도 환경 변수를 위해 ConfigMap 이 사용되며, 저장 공간이 필요한 경우 PVC 가 사용된다. 주기적인 작업이 필요한 경우 Jobs 나 CronJobs 를 사용하고, DaemonSet 의 경우에는 개발자가 직접 생성하지는 않고 시스템 관리자들이 실행해 둔다. HorizontalPodAutoscaler 는 scaling 을 위해 개발자가 직접 포함할 수도 있고, 나중에 Ops 팀에서 추가할 수도 있다. 클러스터 관리자는 LimitRange, ResourceQuota 를 이용해 pod 들의 리소스 사용량을 관리할 수 있다.
어플리케이션이 배포되면, Service 와 함께 Endpoints 가 생성되고, Deployment/StatefulSet 와 함께 ReplicaSet 이 생성된다.
Kubernetes resource 에는 주로 label 을 붙여서 관리하고, 또 대부분 annotation 을 가지고 있어 메타데이터를 저장하여 운영 및 관리를 할 수 있게 해준다.
17.2 Understanding the pod's lifecycle
Pod 와 VM 의 가장 큰 차이점 중 하나는 pod 는 얼마든지 삭제되었다 다시 생성할 수 있다는 점이다. Pod 를 다른 노드로 옮기거나, scale down 이 일어났을 때 pod 를 삭제하곤 한다.
17.2.1 Applications must expect to be killed and relocated
Kubernetes 를 사용하게 되면 pod 들이 (VM 을 사용할 때와 비교했을 때) 훨씬 많이 움직인다. 그리고 이 작업은 자동으로 일어나기 때문에, 개발자는 어플리케이션이 자주 이동되더라도 잘 작동하도록 개발해야 한다.
Pod 이 새롭게 생성되는 경우 변경되는 것들에 의존성이 생기지 않도록 주의해야 한다. 예를 들어, pod 이 죽었다가 다시 생성되면 IP 주소와 hostname 이 변경된다. Stateless 어플리케이션이라면 상관이 없겠지만, stateful 하다면 난감해진다. 물론 StatefulSet 을 사용하면 hostname 은 변하지 않지만 IP 는 여전히 변경된다.
또한 디스크에 쓴 데이터가 유실될 수 있음에 유의해야 한다. Persistent storage 를 사용하지 않으면 컨테이너가 재시작될 때 컨테이너의 파일시스템에 쓴 데이터는 모두 사라진다. 특별히 이러한 상황은 단순히 pod 가 삭제될 때 뿐만 아니라, liveness probe 가 실패하거나, 컨테이너의 프로세스에 오류가 생기거나, OOM 이 발생하는 등 다른 이유로 컨테이너가 재시작될 때 생길 수 있는 문제이므로 조심해야 한다.
위와 같은 데이터 유실을 막으려면 pod-scope 에서 volume 을 사용하면 될 것이다. 새로운 컨테이너가 생기더라도 volume 은 바뀌지 않았을 것이다. 다만 이 해결책도 완벽하지는 않은데, volume 내의 데이터에 문제가 생겨 컨테이너가 반복적으로 죽는 상황이 발생할 수도 있다. 양날의 검이므로 주의해야 한다.
17.2.2 Rescheduling of dead or partially dead pods
만약 컨테이너가 여러 개인 pod 에서 일부 컨테이너가 죽었거나 (partially dead), 모든 컨테이너가 죽었다고 가정해보자. (dead - 컨테이너가 1개인 경우도 포함)
여기서 주의할 점은 만약 이 pod 가 ReplicaSet 등의 관리를 받고 있다고 하더라도, pod 의 rescheduling 이 일어나지 않는다는 점이다. 그래서 만약 desired replica count 가 3 인데 한 pod 에 이상이 생겨 실제로 정상인 pod 는 2개이더라도 Kubernetes 에서는 이에 대해 특별한 조치를 취하지 않고 내버려 둔다. 즉, ReplicaSet controller 는 pod 가 죽어있는지에 대해서 관심이 없다. 단지 존재하는 pod 의 개수가 desired replica count 와 일치하는지만 확인한다.
이렇게 동작하는 이유는, 만약 rescheduling 이 일어난다고 하더라도 컨테이너가 죽은 원인이 해결되지 않을 것이라고 가정하기 때문이다. 어차피 pod 라는 격리된 환경에서 돌아가고 있으므로 rescheduling 하더라도 같은 환경일 확률이 높을 것이다. (항상 그렇지는 않겠지만 대부분의 경우)
17.2.3 Starting pods in a specific order
어플리케이션을 배포할 때 pod 간의 의존성이 있어 특정 순서로 pod 이 생성될 필요가 있을 때가 있다. 하지만 Kubernetes 에게 생성하는 pod 의 순서를 직접 알려줄 방법은 없다. 그렇다고 순서를 맞추기 위해 YAML 파일을 여러 번 POST 하는 방법은 절대 좋은 방법이 아닐 것이다.
물론 하나의 YAML 파일 안에 여러 리소스가 있다면, Kubernetes 는 각 리소스를 파일에 입력된 순서대로 처리하기는 한다. 하지만 이것도 etcd 에 그 순서로 write 가 된다는 것이지, 생성된 리소스가 정상적으로 '실행'되는 순서는 보장하지 않는다.
그래서 Kubernetes 에서는 init container 를 사용하여, 특정 조건이 만족되기 전까지 pod 의 main container 를 실행하지 않도록 한다.
Init containers
이름에서 알 수 있듯이, pod 를 초기화할 때 (시작할 때) 사용하는 컨테이너이다.
Pod 가 가질 수 있는 init container 의 개수에는 제한이 없으며, YAML 에 입력한 순서대로 실행되고 마지막 init container 가 종료되어야 main container 가 실행된다. 그러므로 init container 를 사용하면 main container 의 실행을 지연시킬 수 있으며, init container 에 main container 가 실행될 조건을 걸 수 있다는 것이다.
예를 들어, pod A 가 실행된 다음에 B 가 실행되어야 한다면, pod B 의 init container 에 pod A 가 실행 중인지 확인 (HTTP 요청을 보내는 등) 하는 실행 중이면 종료하는 코드를 넣어 B 의 실행을 A 의 실행 이후가 되도록 할 수 있다.
Pod 에 init container 를 추가하려면 spec.initContainers field 에 적어주면 된다.
spec:
initContainers:
- name: init
image: busybox
command:
- sh
- -c
- 'while true; do ...;'이 pod 를 실행하면 init container 만 실행되게 되고, kubectl get 으로 확인해보면 STATUS 에도 이것이 반영된다.
$ kubectl get pod
NAME READY STATUS RESTARTS AGE
fortune-client 0/1 Init:0/1 0 1m그리고 kubectl logs fortune-client -c init 으로 init container 의 로그도 가져올 수 있다.
Best practices for handling inter-pod dependencies
기본적으로 어플리케이션 내부에서 pod 간의 의존성이 해결되지 않았을 경우를 handling 해야 한다. 추가로 readiness probe 를 적절하게 활용하여 만약 의존성 문제로 pod 이 실행되지 않고 있는 경우 readiness probe 가 실패하도록 설계해야 한다.
17.2.4 Adding lifecycle hooks
Init containers 와 별도로 pod 에는 2가지의 lifecycle hooks 가 있다.
- Post-start hook (시작 후 실행)
- Pre-stop hook (종료 전 실행)
Hook 은 컨테이너 당 만들 수 있으며, 컨테이너 내에서 특정 command 를 실행하거나 HTTP GET 요청을 보낼 수 있게 해준다.
Post-start hook
Post-start hook 는 컨테이너의 프로세스가 시작되자마자 실행된다. 컨테이너 프로세스와 별개로 추가 작업을 할 수 있게 해주며, 컨테이너 안의 프로세스가 3rd-party 앱이라 코드를 직접 건드리지 못하는 경우 post-start hook 이 도움이 될 수 있다.
Hook 는 컨테이너 프로세스와 병렬로 실행되어, 컨테이너 프로세스가 실행되는 것을 기다리지 않는다. (애초에 실행 되었는지 알 방법이 없기도 하다)
그리고 병렬로 실행되지만, hook 이 완료될 때까지 컨테이너는 Waiting 상태에 있게 되고 reason 은 ContainerCreating 이 된다. 그래서 pod 의 상태가 Running 이 아닌 Pending 이 된다.
Hook 의 실행이 실패하거나 non-zero exit code 를 돌려주면 컨테이너가 종료된다.
apiVersion: v1
kind: Pod
metadata:
name: pod-with-poststart-hook
spec:
containers:
- image: luksa/kubia
name: kubia
lifecycle:
postStart:
exec:
command:
- sh
- -c
- "echo 'hook will fail with exit code 15'; sleep 5 ; exit 15"한 가지 아쉬운 점이 있다면, hook 이 stdout 으로 출력하면 출력물을 볼 수 없어 디버깅이 어렵다는 점이다. Hook 이 실패하면 kubectl describe pod 의 events 에서 FailedPostStartHook 만 확인할 수 있다. 만약 출력물을 보고 싶다면 파일에 쓰도록 해야할 것이다. 이 또한 컨테이너가 재시작 되면 날아갈 수 있으므로 emptyDir volume 을 붙여서 그 곳에 쓰도록 하는 것이 좋다.
Pre-stop hook
Pre-stop hook 는 컨테이너가 죽기 전에 실행된다. 컨테이너가 종료될 때 Kubelet 이 pre-stop hook 을 실행하고 컨테이너 프로세스에게 SIGTERM 을 보낸다.
Pre-stop hook 를 사용하면 컨테이너의 graceful shutdown 을 구현할 수 있다. 이외에도 컨테이너 프로세스 종료 전에 해야하는 정리 작업을 할 수도 있다.
Post-start hook 와는 달리 실행 결과와 관계없이 컨테이너 프로세스가 종료된다. 물론 pre-stop hook 이 실패하면 event 에 FailedPreStopHook 이 발생하지만, 컨테이너가 곧 지워지므로 눈치채지 못할 수 있다.
Lifecycle hooks target containers, not pods
Lifecycle hook 은 컨테이너 레벨에서 실행해야 하는 것이지, pod 이 종료될 때 실행하는 것이 아님을 명심해야 한다. Pod 는 그대로이지만, 컨테이너는 중간에 여러 번 교체될 수 있기 때문에 lifecycle hook 에는 container 레벨의 작업이 들어가야 한다. 컨테이너 교체가 일어날 때 pod 전체의 데이터를 정리하는 pre-stop hook 을 사용해서는 안될 것이다.
17.2.5 Understanding pod shutdown
Pod 를 깔끔하게 종료하는 것은 중요하다!
API server 가 HTTP DELETE 요청을 받으면, deletionTimestamp field 를 붙인다. 이 field 값이 존재하는 pod 들은 Terminating 상태가 된다.
이제 Kubelet 이 pod 가 종료되어야 한다는 것을 확인하면, 컨테이너를 하나씩 종료한다. Graceful shutdown 을 위한 시간을 주지만, 기본적으로는 30초를 주며, 이는 수정 가능하다. 이 시점에서 grace period 타이머가 시작되고, 다음 과정이 일어난다.
- Pre-stop hook 이 존재한다면 실행하고, 완료되기를 기다린다.
- 컨테이너에
SIGTERM을 보낸다. - Grace period 안에 종료되지 않았다면
SIGKILL로 강제 종료한다.
Grace period 는 spec.terminationGracePeriodSeconds 로 설정할 수 있다. Pod 를 생성할 때 설정하지 않았더라도, 종료할 때 값을 설정할 수 있다.
$ kubectl delete pod <POD> --grace-period=5그래서 만약 강제로 종료하고 리소스를 삭제하고 싶다면 --grace-period=0 을 주고 --force 옵션을 부여한다.
Shutdown handler
컨테이너에서 실행 중인 어플리케이션은 SIGTERM 에 적절하게 반응하여 종료를 위한 준비를 시작해야 한다.
다만 문제가 있다면 이게 얼마나 걸릴지 예측하기 어렵다는 점이다. 만약 어플리케이션이 stateless 해서 그냥 종료되도 상관이 없다면 문제가 되지 않지만, stateful 하거나, 데이터를 담고 있어 종료 전에 데이터를 옮겨야 한다면 상황이 복잡해진다.
Shutdown procedure 가 반드시 성공하게 하기 위해서, 어플리케이션이 SIGTERM 을 받았을 때 Job 리소스를 생성하고, 그 Job 은 어플리케이션의 데이터를 다른 곳으로 옮겨줄 pod 를 생성하도록 하면 된다. 다만 노드에 문제가 생기는 경우 Job 이 생성되지 않거나, pod 가 생성되지 않을 수 있다. 이런 경우에는 pod 하나를 데이터 이전 용도로 항상 띄워두는 방법을 사용한다.
StatefulSet 을 사용하면 PVC 를 다시 사용할 수 있기는 하지만, scale up 이 오랜 시간 동안 일어나지 않으면 PVC 의 데이터가 그냥 남아있으므로, 이 데이터를 가져와야 하기 때문에 데이터 이전 용 pod 가 필요하다.
얘도 문제가 생기는 경우는 어떻게 하나요...
17.3 Ensuring all client requests are handled properly
당연히 client 의 요청은 잘 처리해야 한다.
17.3.1 Preventing broken client connections when a pod is starting up
Service 의 Endpoint 리소스에 pod 의 IP 가 들어가려면 pod 가 READY 상태가 되어야 하므로 readiness probe 만 잘 사용하면 pod 가 시작될 때 요청을 처리하지 못할 걱정은 하지 않아도 된다.
17.3.2 Preventing broken connections during pod shutdown
크게 두 가지 문제가 있다. 받았는데 처리하지 못한 요청이 있을 수 있고, persistent connection 이 있을 수도 있다.
우선 shutdown 과정이 어떻게 일어나는지 자세히 살펴본다.
API server 가 pod 삭제 요청을 받으면, etcd 에서 상태를 변경한 다음 watch 하고 있는 프로세스에게 알려준다. Kubelet 과 Endpoints controller 가 그 알림을 받게 되고 각자 할 일을 진행한다.
- Kubelet 의 경우 앞서 17.2.5 에서 설명한 shutdown procedure 를 실행한다.
- Endpoints controller 는 우선 해당 pod 를 모든 Service 의 endpoint 에서 제거한다. 제거를 위해서 API server 에 요청을 하기 때문에 API server 는 요청을 받고 처리한 뒤 Endpoints object 를 watch 하고 있는 각 노드의
kube-proxy에게 변경 사실을 알려준다. 그러면kube-proxy는 노드의iptablesrule 을 변경하여 종료 중인 pod 로는 요청이 오지 않도록 한다.
여기서 문제가 되는 부분은 iptables rule 이 변경된다고 해서 이미 맺은 요청이 변경되지는 않는다는 점과, shutdown procedure 보다 iptables rule 수정이 더 오래 걸린다는 점이다.
결국 해결책은 요청을 처리하기 위해 컨테이너의 종료를 미루는 수밖에 없다. kube-proxy 뿐만 아니라 Ingress controller 나 load balancer 의 경우 iptables 를 거치지 않고 바로 pod 에게 요청을 주기도 한다. 그리고 client 측의 load balancing 도 고려하면 결국에는 기다리는 수밖에 없다. 5~10초 지연 만으로도 UX 를 크게 향상시킬 수 있다.
책에서는 완벽한 해결책이 없는 것처럼 서술되어 있는데 진짜 없을까?
요약
Shutdown 을 위해서 다음 절차를 밟아야 한다.
- 몇 초간 대기하고, 새로운 요청을 더 이상 받지 않는다.
- Keep-alive connection 을 모두 종료하는데, 단 요청 중에 중단하지 않도록 유의한다.
- 처리 중인 요청이 모두 끝나기를 기다린다.
- 종료한다.
17.4 Making your apps easy to run and manage in Kubernetes
17.4.1 Making manageable container images
생각해보면 이미지 내에 OS 의 모든 파일이 필요하지는 않다. 불필요한 파일은 다운로드를 늦춰 pod 의 scaling 을 늦출 뿐이다. 그러므로 이미지는 가볍게 유지하는 것이 좋기는 하다.
하지만 이미지 안에 어플리케이션 실행에 필요한 파일만 남겨두게 되면 추후 디버깅이 매우 어려워진다. curl 과 같은 명령은 자주 사용되는데 이미지 안에 없으면 매번 설치해야 한다. 따라서 적절한 도구는 남겨두는 것이 좋다.
17.4.2 Properly tagging your images and using imagePullPolicy wisely
latest 로 이미지를 tag 하면 어떤 버전인지 알 수 없으므로 매우 불편해진다. 또한 latest 를 사용하면 이전 버전의 이미지로 롤백이 불가능해진다. 버전 번호를 잘 붙여서 이미지를 사용해야 한다.
또한 imagePullPolicy 가 Always 면 레지스트리에 접속해서 이미지를 다운받기 때문에 pod 의 시작이 느려질 수 있음에 유의해야 한다. 최악의 경우 레지스트리 접속에 실패하면 pod 이 시작되지 않을 수도 있다.
17.4.3 Using multi-dimensional instead of single-dimensional labels
Pod 를 비롯한 모든 리소스는 label 을 붙이는 것이 좋다. 또, 각 리소스에 label 은 여러개 붙여서 각 key 별로 selection 이 가능하도록 해야 한다. Label 에 자주 사용되는 key 들은 다음과 같은 것들이 있다.
- 이름
- Tier (프론트엔드/백엔드 등)
- Environment (dev/staging/prod/qa)
- 버전
- 릴리스 타입 (stable, canary 등)
17.4.4 Describing each resource through annotations
추가 정보를 기입하기 위해 annotation 을 사용하면 된다. 리소스를 설명하는 annotation 이 있으면 좋고, 담당자 연락처가 들어가는 것도 좋다. 혹은 MSA 에서 이 pod 를 사용하는 다른 마이크로서비스의 목록을 기입하는 것도 좋다.
17.4.5 Providing information on why the process terminated
로그 파일에 디버깅을 위한 정보를 남겨두는 것이 권장된다. 로그 파일로 남기는 방법도 있으며, Kubernetes 기능 중에 termination log 를 남기는 방법이 있다.
컨테이너 정의에서 terminationMessagePath 를 설정해 주면 (기본값은 /dev/termination-log) 해당 파일로 컨테이너가 죽은 이유를 기록할 수 있게 된다. 그리고 이는 kubectl describe pod 에서 Last State 의 Message 에서 확인할 수 있게 된다.
17.4.6 Handling application logs
기본적으로 어플리케이션 로그는 stdout 으로 출력하면 kubectl logs 로 읽을 수 있지만, 파일로 저장할 수도 있다. 이 경우,
$ kubectl exec <POD> cat <LOG_FILE_PATH>로 내용을 읽을 수 있다. 만약 밖으로 로그를 복사하고 싶으면 kubectl cp 명령을 사용한다.
$ kubectl cp <POD>:<LOG_FILE_PATH> <PATH_IN_LOCAL_MACHINE>참고로 반대 방향도 된다.
Centralized Logging
Production 환경에서는 클러스터 전체에 적용되는 중앙화된 로깅 솔루션을 적용하는 것이 좋다. Pod 이 죽으면 로그가 같이 날아가기 때문에, 로그를 중앙으로 모아주고 관리하고 분석해주는 것이 필요하다.
Kubernetes 에 내장된 기능은 없지만 FlunetD 가 주로 사용된다. (주로 DaemonSet 으로 실행된다)
FluentD 를 사용하게 되면 컨테이너의 로그를 수집하고, pod-specific information 을 태그하여 중앙으로 모아준다. EFK (Elasticsearch, FluentD, Kibana) 를 사용하는 방법도 있다.
Sidecar 컨테이너에 로그를 처리해주는 프로세스를 띄워도 된다.
Multi-line logs
로그가 만약 여러 줄에 걸쳐서 찍힌다면 (Java Exception stack trace 처럼) 로그 output 을 JSON 형태로 고치는 것이 좋다. 다만 이렇게 하면 kubectl logs 에서 보이는 내용이 인간 친화적이지 않다.
해결 방법으로는 JSON 로그는 파일로 내보내고, stdout 에는 원본을 찍어 사람이 보기 편하도록 하면 된다.
17.5 Best practices for development and testing
정해진 정답은 없지만, 권장 사항을 몇 가지 살펴본다. 각자 환경에 알맞은 방법을 택하면 된다.
17.5.1 Running apps outside of Kubernetes during development
앱 자체는 로컬에서 실행하고, 환경 변수만 적절하게 조절하여 어플리케이션의 다른 부분에 접속하면 된다. Service 를 사용해야 하는 경우 Service type 을 NodePort 등으로 둘 수도 있을 것이다.
만약 Kubernetes API server 에 접속해야 한다면 secret 만 복사해서 가져오면 된다. 클러스터 내부인지 검사하지 않는다.
또한 컨테이너 내부에서 작업을 수행해야 한다면, 로컬 스토리지를 mount 해서 개발하면 된다. 그러면 수정할 때 매번 다시 이미지를 빌드하지 않아도 된다.
17.5.2 Using Minikube in development
- minikube 를 사용해서 로컬의 파일을 minikube VM 에 mount 하고 이를 다시
hostPath를 이용해 컨테이너 안에 mount 할 수 있다. - minikube 의 Docker daemon 을 활용하면 매번 이미지를 레지스트리에 push 할 필요가 없어진다.
eval $(minikube docker-env)를 이용하면DOCKER_HOST환경 변수가 minikube 의 Docker daemon 으로 변경된다. 이미지를 새롭게 빌드한 뒤에는 pod 을 재시작 하면 된다.
17.5.3 Versioning and auto-deploying resource manifests
Git 등의 version control system 을 활용해 manifest 들을 저장해 두면 versioning 이나 변경 사항을 기록하기 편리하다. 또한 kube-applier 와 같은 툴을 사용하면 version control system 에 등록된 manifest 의 상태를 자동으로 적용해 주기도 한다.
17.5.4 Introducing Ksonnet as an alternative to writing YAML/JSON manifests
YAML 이 불편하면 Ksonnet 을 사용할 수 있다. JSON 을 만들기 위한 template language 인 Jsonnet 을 바탕으로 만들어졌고, Ksonnet 을 사용하면 resource manifest 를 손쉽게 작성할 수 있다.
변수에 값을 저장하는 기능도 지원한다.
local k = import "../ksonnet-lib/ksonnet.beta.1/k.libsonnet";
local container = k.core.v1.container;
local deployment = k.apps.v1beta1.deployment;
local kubiaContainer =
container.default("kubia", "luksa/kubia:v1") +
container.helpers.namedPort("http", 8080);
deployment.default("kubia", kubiaContainer) +
deployment.mixin.spec.replicas(3)17.5.5 Employing Continuous Integration and Continuous Delivery
Fabric8 project 를 참고.
Discussion & Additional Topics
'Computer Science > Kubernetes' 카테고리의 다른 글
| Chapter 18. Extending Kubernetes (0) | 2021.09.04 |
|---|---|
| Chapter 16. Advanced scheduling (0) | 2021.08.15 |
| Chapter 15. Automatic scaling of pods and cluster nodes (1) | 2021.07.18 |
| Chapter 14. Managing pods' computational resources (0) | 2021.07.11 |
| Chapter 13. Securing cluster nodes and the network (0) | 2021.06.29 |
| Chapter 12. Securing the Kubernetes API server (0) | 2021.06.06 |




댓글