주요 내용
- 노드의 taint 와 pod tolerations
- Node affinity rules 사용
- Pod affinity, anti-affinity 사용
16.1 Using taints and tolerations to repel pods from certain nodes
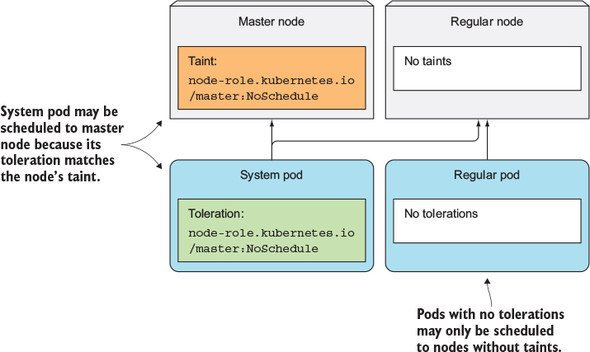
Pod 가 특정 노드에 schedule 되기 위해서는 그 노드의 taint 를 tolerate 할 수 있어야 한다.
16.1.1 Introducing taints and tolerations
Taint 는 key, value, effect 로 이루어져 있고, <key>=<value>:<effect> 로 표현된다. kubectl describe node [NODE_NAME] 을 해보면 Taints 항목에서 확인할 수 있다.
예를 들어 node-role.kubernetes.io/master:NoSchedule 이라는 taint 가 노드에 설정되어 있으면, 이 값을 tolerate 에 가지고 있지 않은 pod 는 이 노드에서 실행될 수 없게 된다.
kubectl describe pod 를 이용해 pod 설명을 보면 Tolerations 항목에서 확인할 수 있다.
Taint 의 effect 종류에는 3가지가 있다.
NoSchedule: taint 를 tolerate 하지 않는 pod 들은 schedule 될 수 없다.PreferNoSchedule: taint 를 tolerate 하지 않더라도 만약 scheduling 될 수 있는 다른 노드가 없을 때는 이 노드에 scheduling 가능하다.NoExecute: 이 taint 를 노드에 추가하면, 이를 tolerate 하지 않는 pod 들은 전부 삭제된다.
16.1.2 Adding custom taints to a node
$ kubectl taint node <NODE> <key>=<value>:<effect>16.1.3 Adding toleration to pods
apiVersion: extensions/v1beta1
kind: Deployment
metadata:
name: prod
spec:
replicas: 5
template:
metadata:
labels:
app: prod
spec:
containers:
- args:
- sleep
- "99999"
image: busybox
name: main
tolerations: # tolerations
- key: node-type
operator: Equal
value: production
effect: NoSchedulekey 와 value 가 같을 때 (operator: Equal) taint 를 tolerate 할 수 있게 된다.
16.1.4 Understanding what taints and tolerations can be used for
기본적으로 taint 와 toleration 은 모두 여러 개 가질 수 있다.
Taint 의 경우 key 만 있고 value 는 없어도 된다.
Toleration 의 경우 operator: Equal 을 이용해서 특정 value 만 처리할 수 있으며, value 가 없거나 상관 없는 경우에는 key 가 존재하는지만 확인하기 위해 operator: Exists 를 사용할 수 있다.
Scheduling 을 위해 사용
Taint 를 사용하면 NoSchedule effect 를 이용해 새로운 pod 들이 노드에 schedule 되는 것을 막을 수 있고, PreferNoSchedule effect 로 선호하지 않는 pod 을 정의할 수 있으며, NoExecute 를 이용해 존재하는 pod 도 삭제할 수 있게 된다.
이외에도 taint/toleration 을 이용해서 클러스터를 분할해서 여러 팀이 사용하게 할 수 있다.
16.2 Using node affinity to attract pods to certain nodes
Taint 를 이용하면 특정 노드에 pod 이 scheduling 되지 않도록 할 수 있었다. 반면 node affinity 를 이용하면 pod 가 schedule 될 수 있는 노드를 정할 수 있다.
우선 node selector 는 결국 deprecated 될 것이라는 점을 유의하고, node affinity 를 사용하는 것이 권장된다.
Node selector 와 유사하게 pod 마다 node affinity rule 을 가질 수 있다. 이 rule 들은 hard requirement 나 preference 를 정할 수 있게 해준다.
16.2.1 Specifiying hard node affinity rules
Chapter 3 의 예제에서 GPU 가 필요한 pod 를 GPU 노드에만 scheduling 되도록 했었다. 그 때는 nodeSelector field 를 지정해 줬었다.
...
spec:
nodeSelector:
gpu: "true"
...반면 node affinity rule 을 사용하여 다음과 같아진다.
spec:
affinity:
nodeAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
nodeSelectorTerms:
- matchExpressions:
- key: gpu
operator: In
values:
- "true"requiredDuringSchedulingIgnoredDuringExecution attribute 는 사실
requiredDuringScheduling: Scheduling 에 필요한 rule 들을 정의IgnoredDuringExecution: 노드에서 이미 실행 중인 pod 에는 rule 이 영향을 주지 않는다
는 의미이다.
이외에 nodeSelectorTerms 와 matchExpressions 는 노드의 label 에서 일치하는 것을 찾으라는 의미이다.
따라서 이 pod 는 gpu=true label 이 있는 노드에만 scheduling 된다.
16.2.2 Prioritizing nodes when scheduling a pod
Node affinity 를 이용했을 때의 가장 큰 장점은 노드에 우선순위 (선호도)를 두어 Scheduler 가 scheduling 할 때 이를 반영할 수 있다는 점이다. 이는 preferredDuringSchedulingIgnoredDuringExecution field 를 이용해서 할 수 있다.
우선 노드에 label 이 되어있어야 하고, pod 를 생성할 때 다음과 같이 생성하면 된다.
spec:
affinity:
nodeAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80 # 가중치 설정 가능
preference:
matchExpressions:
- key: availability-zone
operator: In
values:
- zone1
- weight: 20
preference:
matchExpressions:
- key: share-type
operator: In
values:
- dedicatedpreferredDuringSchedulingIgnoredDuringExecution 으로 선호도 규칙을 설정할 수 있고, weight 를 주어 가중치를 설정할 수 있다. 80:20 이므로 첫 번째 규칙이 4배 더 중요한 것이다.
위 규칙에 의하면 노드의 우선순위 순서는 다음과 같아진다.
availability-zone=zone1,share-type=dedicatedavailability-zone=zone1,share-type은dedicated가 아님availability-zone이zone1이 아니고,share-type=dedicated- 이외의 노드
16.3 Co-locating pods with pod affinity and anti-affinity
앞서 살펴본 node affinity 는 pod 과 노드 사이의 affinity 를 정한 것이었는데, 때로는 pod 사이의 affinity 가 필요할 때도 있다. 예를 들어 프론트엔드/백엔드 pod 를 같은 노드에 띄우면 latency 가 줄어들게 될 것이다. 그렇다고 두 pod 를 특정 노드에 띄우라고 지시하기 보다는 Kubernetes 가 알아서 하라고 하는 것이 좋을 것이다.
16.3.1 Using inter-pod affinity to deploy pods on the same node
예시로 백엔드 pod 하나와 프론트엔드 pod 5개를 띄우는 상황을 고려해 보자.
$ kubectl run backend -l app=backend --image busybox -- sleep 999999여기서 확인할 부분은 app=backend label 이 부여되었다는 점이다. 이 label 을 이용해 podAffinity 를 설정하기 때문이다.
프론트엔드 pod 에서 다음과 같이 설정한다.
apiVersion: apps/v1
kind: Deployment
metadata:
name: frontend
spec:
replicas: 5
template:
metadata:
labels:
app: frontend
spec:
affinity:
podAffinity:
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
app: backend
containers:
- name: main
image: busybox
args:
- sleep
- "99999"requiredDuringSchedulingIgnoredDuringExecution 으로부터 hard requirement 이고, topologyKey field 로 인해 app=backend label 을 가진 pod 와 같은 노드에 띄워지게 된다.
여기서 백엔드 pod 를 지우고 다시 띄우면, 백엔드 pod 에는 affinity 설정이 없음에도 불구하고 프론트엔드 pod 과 같은 노드로 scheduling 된다. Scheduler 가 노드를 고를 때 프론트엔드 pod 에 있는 affinity rule 를 반영하게 된다.
16.3.2 Deploying pods in the same rack, availability zone, or geographic region
Same availability zone
topologyKey 의 값을 failure-domain.beta.kubernetes.io/zone 으로 설정하면 된다.
Same geographical region
topologyKey 의 값을 failure-domain.beta.kubernetes.io/region 으로 설정하면 된다.
topologyKey 의 작동 방식
Scheduler 가 scheduling 을 수행할 때 pod 의 podAffinity 설정을 확인하는데, 우선 label selector 를 이용해 pod 의 목록을 조회한다. 그 다음 pod 들이 띄워져 있는 노드를 모두 조사하여 노드의 label 들 중에서 topologyKey 에 대한 value 가 같은 노드에 scheduling 한다.
예를 들어 topologyKey 가 rack, label selector 는 app=backend 라고 하자. app=backend label 을 가진 pod 가 만약 노드 1에 띄워져 있다면, 노드 1의 label 을 조회하여 rack 이라는 key 가 존재하는지 확인하고, 그 key 에 대한 value 가 rack2 라면 새로운 pod 는 rack=rack2 label 을 가진 노드로만 scheduling 이 일어난다.
label 을 잘못 설정하거나 그러면 분명 꼬이는 경우가 있을 것 같은데 그런 경우에는 어떻게 에러 핸들링이 되는지 궁금하다.
minikube는 single node cluster 라 테스트가 불가능...
추가로 label selector 가 동작할 때 같은 namespace 에서만 조회한다.
16.3.3 Expressing pod affinity preferences instead of hard requirements
Node affinity 에서와 마찬가지로 hard requirement 대신 preference 를 설정할 수 있고, 필드 명도 preferredDuringSchedulingIgnoredDuringExecution 이다. 마찬가지로 선호한다는 의미이고, 반드시 지켜지지 않을 수도 있다.
spec:
affinity:
podAffinity:
preferredDuringSchedulingIgnoredDuringExecution:
- weight: 80
podAffinityTerm:
topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
app: backend16.3.4 Scheduling pods away from each other with pod anti-affinity
이번에는 반대로 pod 가 서로 같은 노드에 scheduling 되지 않도록 하고 싶을 때, anti-affinity 를 사용하면 된다.
대표적으로 만약 pod 에서 실행 중인 어플리케이션이 서로의 performance 에 영향을 준다면 다른 노드에 배치하고 싶을 수 있으며, 또 고가용성(HA)를 위해 여러 availability zone/region 에 pod 를 띄우고 싶은 경우 anti-affinity 가 필요하다.
spec:
affinity:
podAntiAffinity: # podAntiAffinity 이다
requiredDuringSchedulingIgnoredDuringExecution:
- topologyKey: kubernetes.io/hostname
labelSelector:
matchLabels:
app: frontend전체적인 규칙은 podAffinity 와 비슷하다. 마찬가지로 preferredDuringSchedulingIgnoredDuringExecution 를 이용하면 hard requirement 가 아닌 preference 를 지정할 수 있다.
Discussion & Additional Topics
'Computer Science > Kubernetes' 카테고리의 다른 글
| Chapter 18. Extending Kubernetes (0) | 2021.09.04 |
|---|---|
| Chapter 17. Best practices for developing apps (0) | 2021.08.15 |
| Chapter 15. Automatic scaling of pods and cluster nodes (0) | 2021.07.18 |
| Chapter 14. Managing pods' computational resources (0) | 2021.07.11 |
| Chapter 13. Securing cluster nodes and the network (0) | 2021.06.29 |
| Chapter 12. Securing the Kubernetes API server (0) | 2021.06.06 |



댓글